March 8, 2026 · 6 min read
Separating Surface Variation from Conceptual Variation in LLM Outputs
- #ai
- #creativity
- #llm
- #research
- #convergence
Separating Surface Variation from Conceptual Variation in LLM Outputs
In the first round of Human Touch experiments, I tested whether placing LLM agents in structured creative environments with synthetic backstories could produce measurably more novel outputs. In the next phase of the experiments (Phase 1B), I considered a more fundamental question: when you run the same prompt through a model many times, how much do the outputs actually differ from each other, and at what level?
I ran ~3,300 outputs across Claude Sonnet 4.6, Claude Opus 4.5, and GPT-5.2 to find out.
Three layers of output variation
LLM output varies along three separable layers, and measuring them independently is the key to understanding what’s going on.
Surface variation captures word choice and phrasing. Measured with cosine distance between full-text embeddings.
Conceptual variation captures idea-level differences: the frameworks, structures, and reasoning patterns underneath the words. Measured with cosine distance between abstract-summary embeddings.
Specific variation captures factual and argument overlap: whether outputs cite the same examples, make the same claims, and reach the same conclusions. Measured with Jaccard distance between extracted key claims.
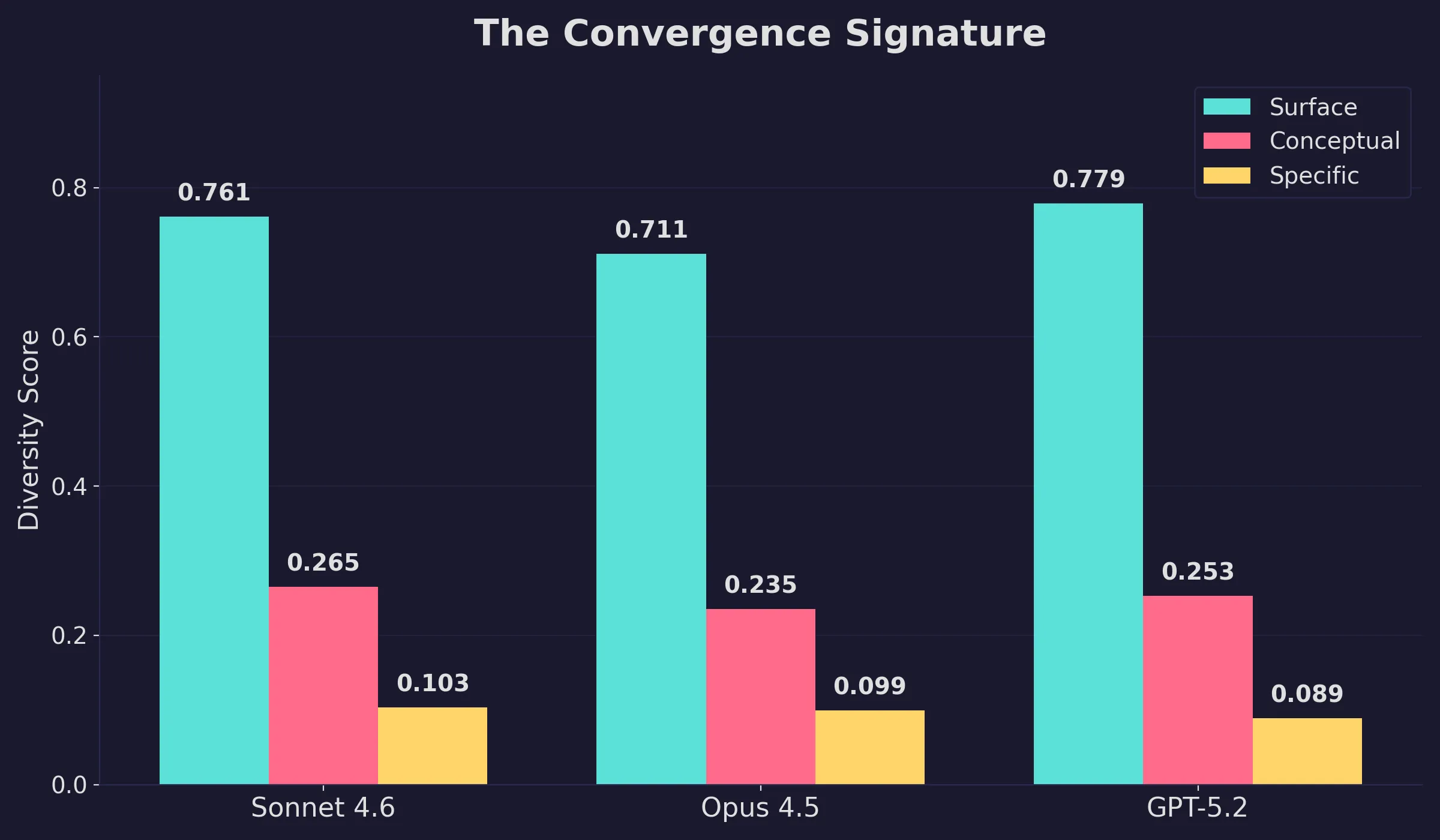
All scores run from 0.0 (identical outputs) to 1.0 (maximally different). A conceptual score of 0.25 means that any two outputs to the same prompt share about 75% of their idea-level content. A specific score of 0.10 means over 90% overlap in the actual claims, examples, and arguments cited.
All three models rephrase freely (surface scores of 0.71-0.78) while cycling through the same core ideas (conceptual scores of 0.23-0.27) and arguments (specific scores of 0.09-0.10). The pattern holds across model families, which points to something fundamental about how transformers organize knowledge.
Temperature changes the words
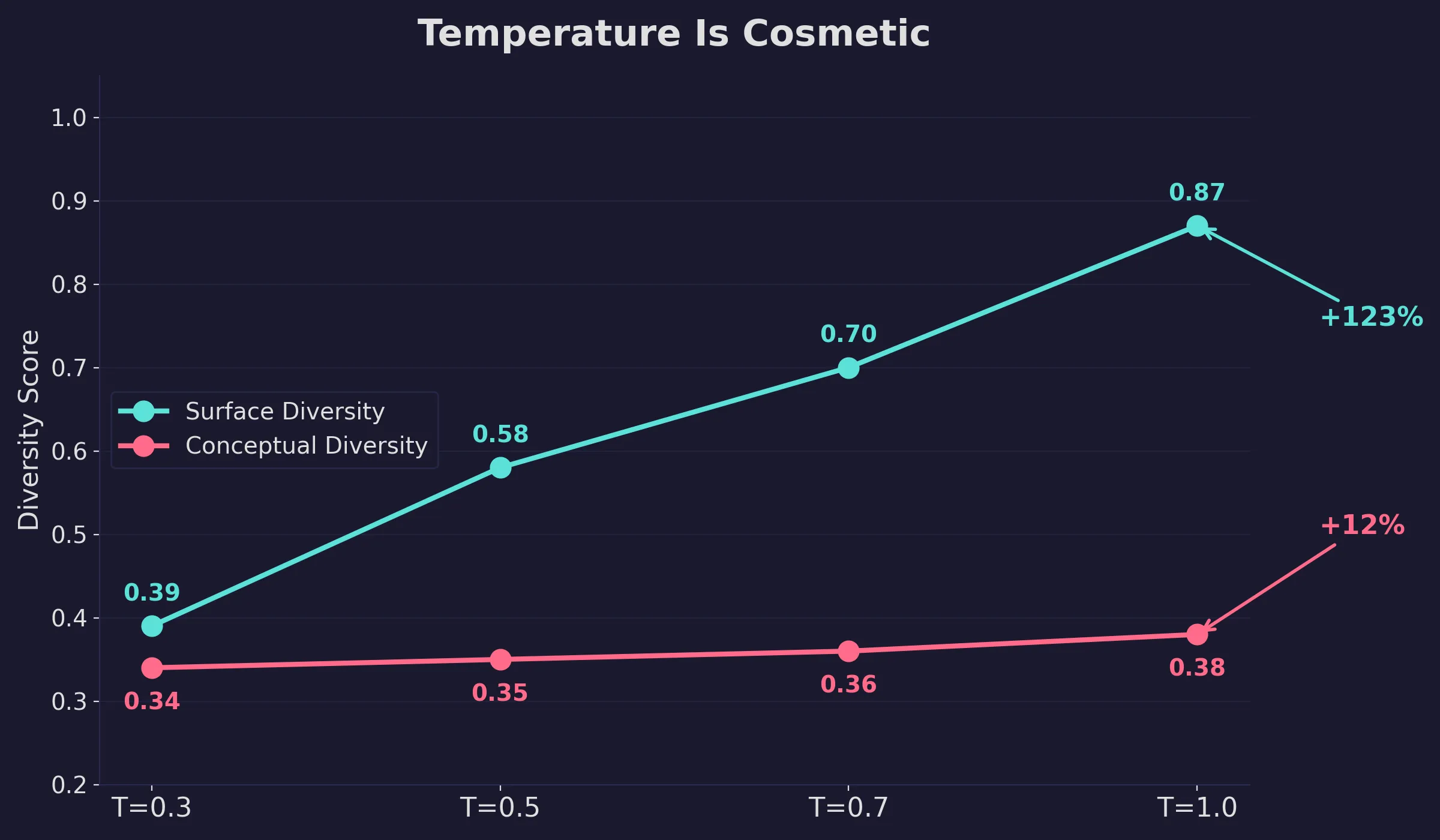
Another lever I tested when interacting with the LLM models was the Temperature (T) value. Surface variation more than doubles from T=0.3 to T=1.0. Conceptual variation moves by 0.04. The temperature lever can increase variation in outputs (like for brainstorming, reframing, or creative writing), but you’re still getting new phrasing of the same ideas.
Most prompt techniques fail to generalize
Convergence varies by prompt type. I tested five benchmark types ranging from historical analysis to creative fiction, and the more factual anchors a prompt provides, the tighter the outputs cluster.
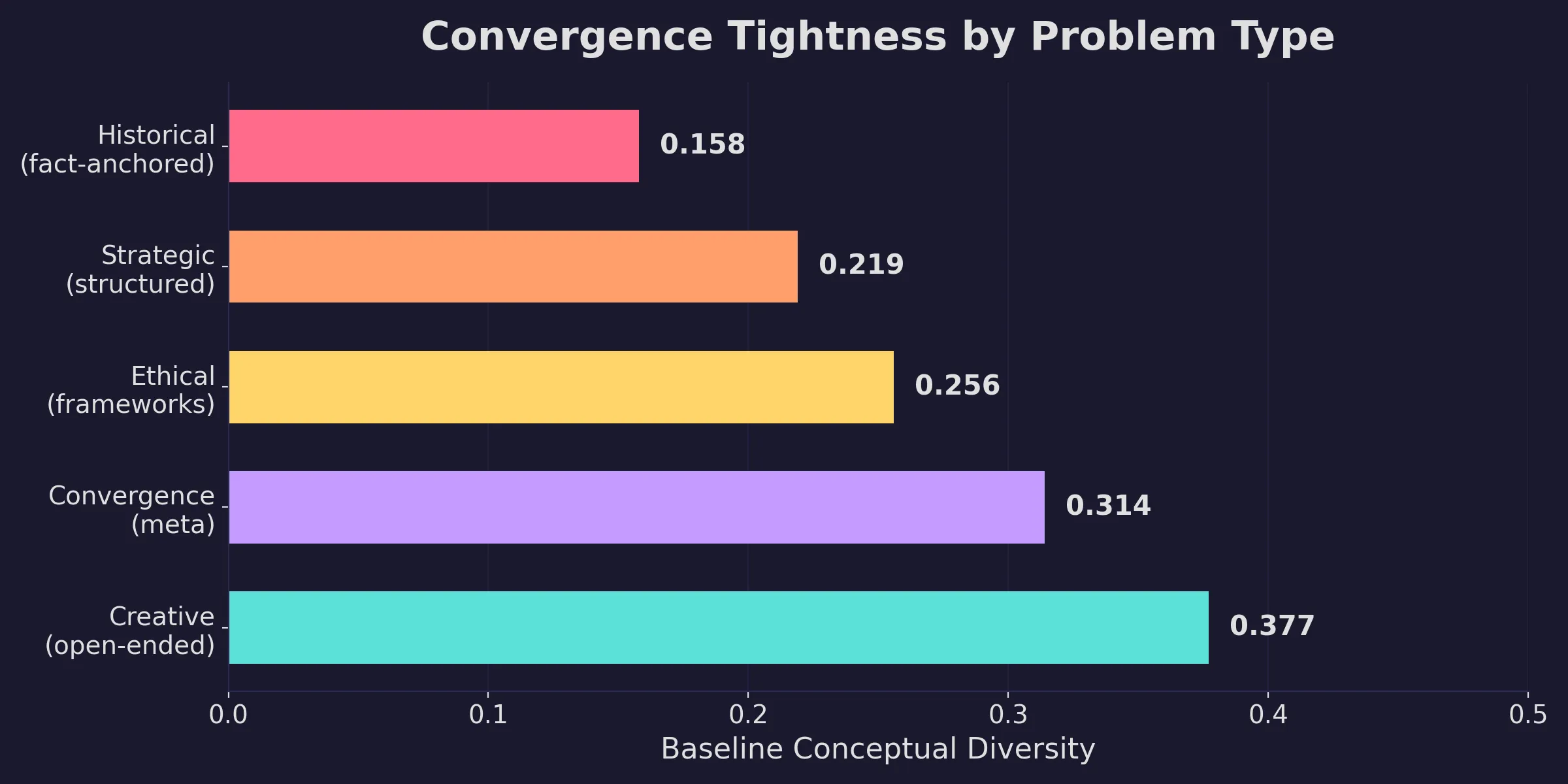
Historical analysis (reconstructing a decision framework) scored 0.158 on conceptual variation. Creative writing scored 0.377. This ranking held across all three models. It tracks what you’d expect from the structure of the prompts themselves: a prompt about a specific historical decision has a narrow set of defensible answers, while a creative fiction prompt has a wide-open solution space. The fact that the scores reflect that gradient is a good sign that the measurement is capturing something real.
With that baseline in mind, I started with the approaches people commonly suggest for getting varied outputs: light persona changes (“you are a young woman,” “respond in second person”) and similar surface-level tweaks. Average conceptual change: +0.023. Noise.
Then I tested five techniques that had performed well in Phase 1’s single-model experiments, this time across all five benchmarks, all three models, 10 runs per condition.
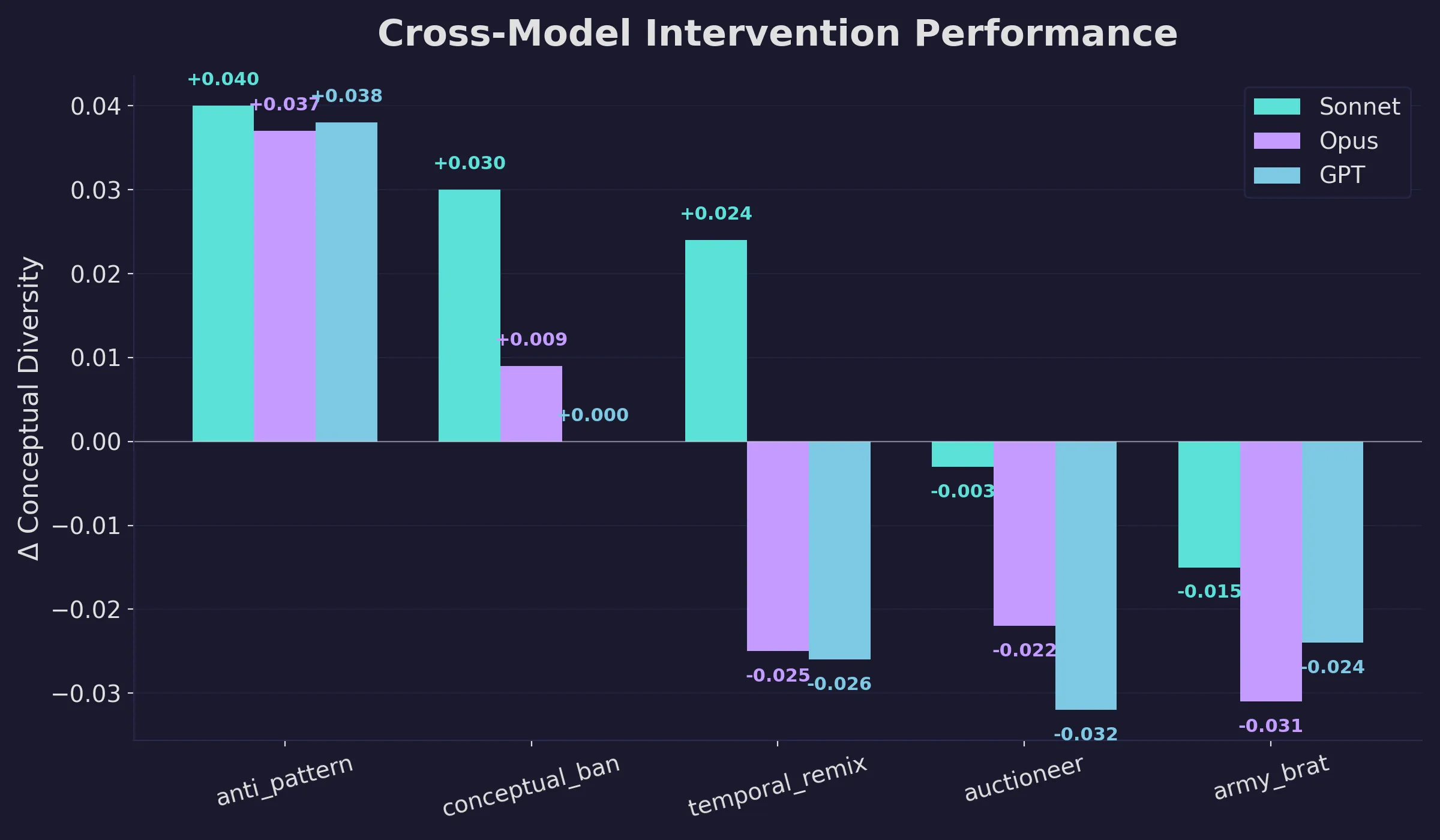
One technique worked reliably: instructing the model to first identify the most common approaches to the problem and then deliberately avoid them (“anti-pattern avoidance”). It was the only technique with a positive effect on all three models, averaging +0.038 conceptual variation over baseline. In absolute terms, that looks small. But baseline conceptual variation is only 0.23-0.27, so a +0.038 shift represents roughly a 15% relative increase in idea-level diversity. For the most convergent benchmarks, the effect was larger: historical analysis saw +0.10 to +0.15, which cuts the conceptual overlap from ~84% to ~69%. Anti-pattern avoidance works by making the model’s own convergence visible to itself.
Banning specific common concepts from appearing worked on Sonnet (+0.030) but faded on the other two models. The remaining three techniques (time-shifting the problem to a different era, strong occupational personas, and formative memory implants) had shown promise in single-model testing and failed to hold up across model families.
Standard LLM-as-judge evaluation can’t detect this kind of convergence at all. The correlation between a judge’s “novelty” score and actual uniqueness within the output set was 0.10-0.25. Judges evaluate each response in isolation, scoring how original it reads. They can’t see that an original-sounding response shares its framework with most of the other responses to the same prompt. Measuring convergence requires comparing outputs against each other at the embedding level.
Two dimensions of breaking convergence
My original metric measured how similar a technique’s outputs were to each other (within-group variation). I was missing a second dimension: whether the technique moved the model’s outputs to a different region of idea-space from where they’d normally land.
I added a displacement metric: the distance between the average position of a technique’s outputs and the average position of the control outputs in embedding space.
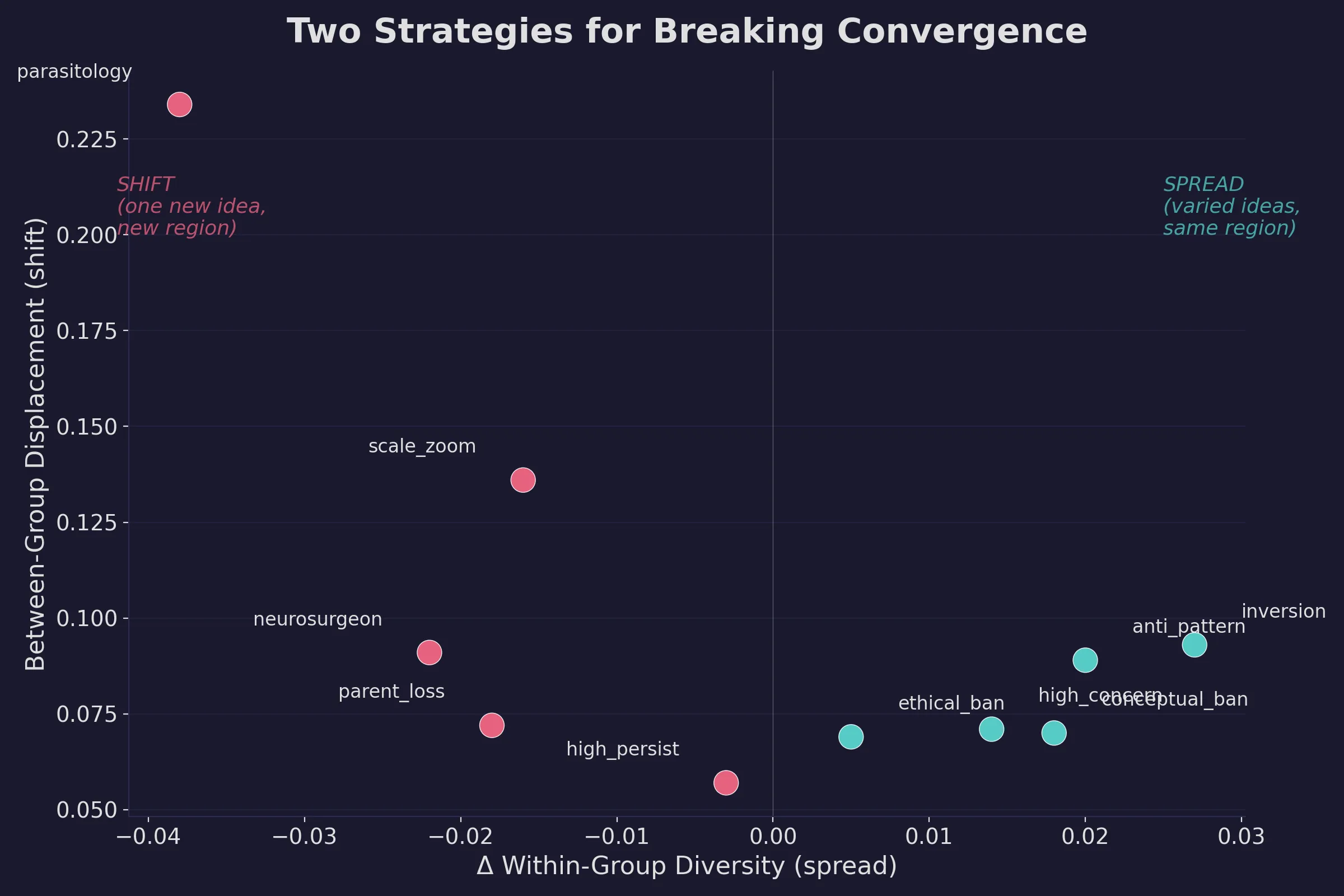
The persona-based techniques I’d dismissed turned out to be the strongest on this second dimension. Constraining the model to reason through the lens of parasitic co-evolution, for example, produced the highest displacement in the dataset (0.234), meaning its outputs landed farther from the control region than any other technique. But those displaced outputs were tightly clustered. The technique reliably moved to a new angle and stayed there.
Anti-pattern avoidance and assumption inversion, however, spread outputs out more while staying closer to the default region.
This creates two practical strategies:
- Spread techniques
- Creates varied ideas that partially overlap with what you’d get from a bare prompt. Useful for brainstorming when you want options.
- Examples: anti-pattern avoidance, assumption inversion, concept banning
- Shift techniques
- Creates one consistent new perspective that’s genuinely different from the default. Useful when you want a specific alternative angle.
- Examples: domain-specific reasoning constraints, strong occupational personas
Measurement artifacts
The initial analysis found a strong negative correlation (r = -0.63) between spread and shift, suggesting a fundamental tradeoff: techniques that push the model to a new region also make it converge more tightly there. This would have been an important architectural constraint for building multi-agent creative systems.
When I rebuilt the scorer with a proper 3-layer embedding approach (the original used a cruder text-similarity measure for one of the layers), the correlation reversed to r = +0.39. Many techniques naturally spread and shift simultaneously. The tradeoff was an artifact of how I was measuring rather than a property of the techniques themselves.
The corrected analysis also clarified which techniques were most versatile across benchmark types. Limiting the model’s available resources or concepts appeared in the top performers for three of five benchmarks. Time-shifting (asking the model to approach the problem from a different historical era) produced the highest within-group variation in the dataset. And assumption inversion scored high on both spread and shift, making it one of the few techniques that reliably does both.
Structural constraints had a 75% rate of producing genuinely diverse output sets. Persona-based techniques more often created a single distinct perspective. For maximizing the range of ideas across multiple runs, constraints on how the model reasons outperform constraints on who it pretends to be.
What I’m building on this
These findings set up the next phase of the experiment: multi-agent collaboration.
A single model, prompted once, converges. Prompting it ten times with the same input produces ten phrasings of roughly the same argument. Structural techniques can widen the conceptual range by ~15%, and domain-specific constraints can push outputs into entirely new regions of idea-space, but a single prompt technique still produces a single type of variation.
The next step is to combine them. Put several structurally different prompt techniques in parallel, each pushing toward a different region, and then compare their outputs against each other at the embedding level. A judge model rating individual responses will score most of them as original-sounding. Comparing them to each other reveals the actual overlap, and lets you select for genuine diversity rather than the appearance of it.
That’s the architecture I’m testing in Phase 2: purpose-built agent profiles that pair specific personas with specific constraint types, running in parallel on the same problem. The spread/shift data from this phase tells me which combinations to try first.